
ファインチューニングとは、既存のAIモデルに追加学習を行い、特定の業務や目的に合わせて性能を調整する手法です。
ファインチューニングは、AIを自社専用に育てる有効な手段です。一方で、目的設定やデータ準備を誤ると、期待した精度が出ないこともあります。導入を検討する際は、仕組みと使い分けを理解したうえで、自社に適した方法を選ぶことが重要です。

ファインチューニングとは
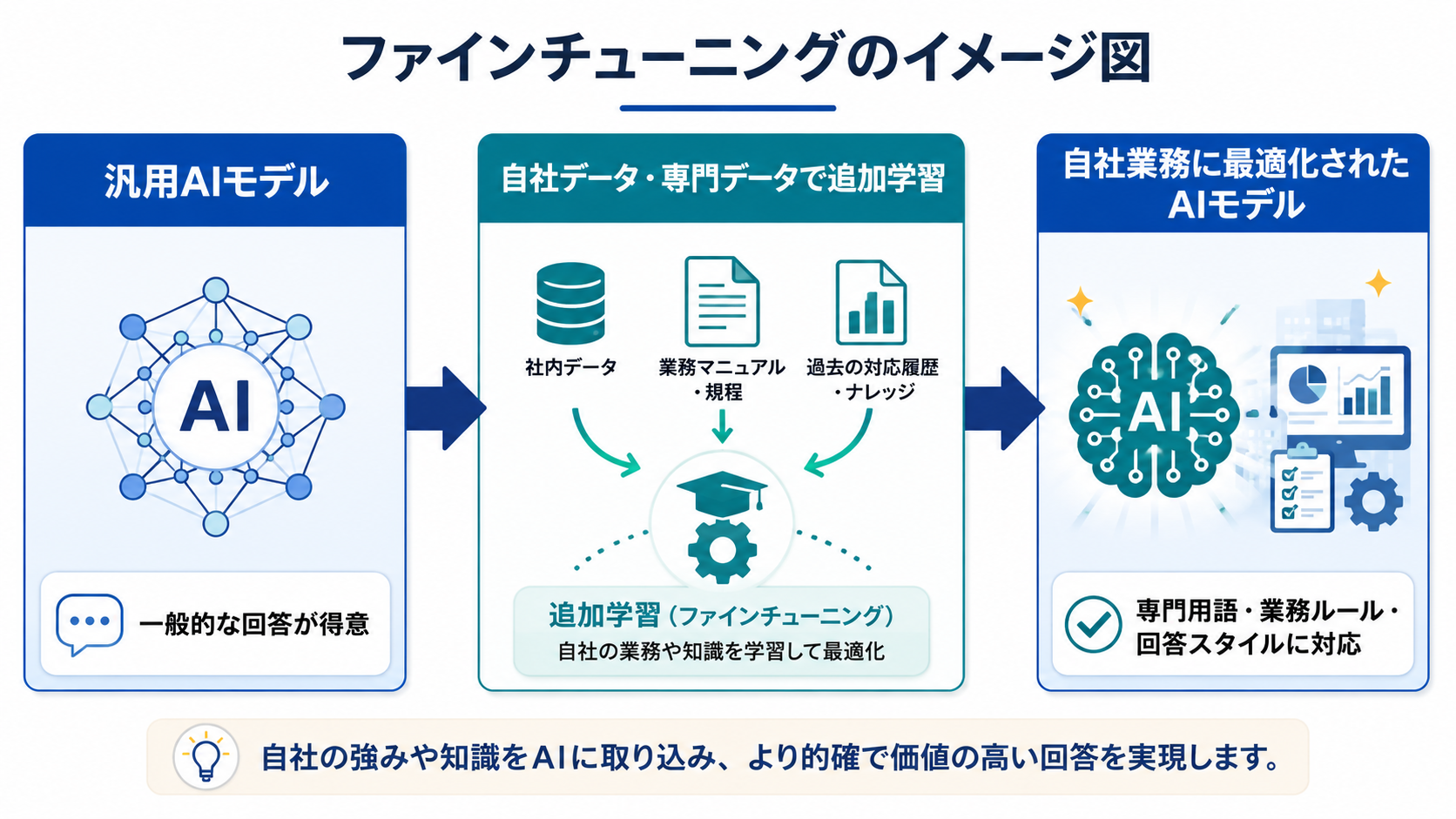
ファインチューニングとは、すでに大量のデータで学習済みのAIモデルに対して、特定の目的に合わせた追加学習を行う手法です。
ゼロからAIを開発するのではなく、既存モデルの能力を活かしながら、自社業務や専門領域に合わせて調整する点が特徴です。
ファインチューニングの仕組み
学習済みモデルとは、あらかじめ大量の文章、画像、音声などを学習し、基本的なパターンを理解しているAIモデルを指します。生成AIであれば、一般的な文章生成、要約、分類、質問応答などを行う土台の能力を持っています。
ただし、汎用モデルはあくまで幅広い用途に対応するためのモデルです。そのため、自社特有の専門用語、業務ルール、顧客対応方針、ブランドトーンまでは十分に反映できない場合があります。
そこで、ファインチューニングを行います。たとえば、次のようなデータを追加で学習させます。
- 自社の問い合わせ対応履歴
- 業界特有の専門用語を含む文書
- 正解例として使える質問と回答のセット
- 企業のトーン&マナーに沿った文章例
- 画像認識であれば、自社業務に近い画像とラベル
これにより、汎用的なAIを「自社業務に詳しい専門家」に近づけることができます。
イメージとしては、一般的な知識を持つ新入社員に対して、自社の商品知識、対応ルール、業界事情を研修するようなものです。基本的な理解力はすでに備わっているため、必要な領域に絞って追加教育を行うことで、短期間で実務に近い対応ができるようになります。
プレトレーニング(事前学習)との違い
プレトレーニングとは、AIモデルが大量のデータから基本的な知識や言語能力を学ぶ工程です。日本語では「事前学習」と呼ばれます。
プレトレーニングでは、文章の構造、単語の関係、文脈の読み取り方、画像の特徴など、幅広いパターンを学びます。人にたとえると、学校教育や基礎トレーニングのような段階です。
一方、ファインチューニングは、プレトレーニングで得た基礎能力を活かして、特定の業務や目的に合わせて追加学習する工程です。
たとえば、次のように考えるとわかりやすくなります。
- プレトレーニング:基礎体力づくり
- ファインチューニング:特定競技に向けた専門練習
すでに文章を理解できるAIに対して、医療文書の分類、法律文書の要約、製造業の不良検知、カスタマーサポートの回答生成など、特定業務に必要な知識や出力形式を学ばせるのがファインチューニングです。
| プレトレーニング | ファインチューニング | |
|---|---|---|
| 目的 | AIの基礎能力を身につける | 特定業務や目的に合わせて調整する |
| 学習内容 | 大量の一般データ | 自社データ、専門データ、回答例など |
| イメージ | 基礎体力づくり | 専門スキルの特訓 |
| 対象範囲 | 幅広い知識やパターン | 業務固有の知識、出力形式、判断基準 |
| 企業での活用場面 | 基盤モデルの開発 | 自社向けAI、業務特化AIの構築 |
プレトレーニングとファインチューニングは、どちらもAIの性能に関わる重要な工程です。ただし、企業が自社業務に合わせてAIを活用する際に検討するのは、主にファインチューニングです。
ファインチューニングとRAG、転移学習の特徴とカスタマイズ手法の比較
AIを自社向けにカスタマイズする方法は、ファインチューニングだけではありません。
代表的な手法には、RAG、転移学習、プロンプト設計などがあります。なかでもファインチューニング、RAG、転移学習は混同されやすいため、それぞれの役割を理解しておくことが重要です。
| ファインチューニング | RAG | 転移学習 | |
|---|---|---|---|
| アプローチ方法 | 学習済みモデルに追加学習を行う | 外部データを検索して回答に反映する | 既存モデルの知識を別タスクへ転用する |
| 参照情報元 | 学習データとして取り込んだ情報 | 社内文書、DB、FAQ、ナレッジベースなど | 既存モデルが学習済みの特徴量 |
| モデルの更新有無 | モデル自体を調整する | モデル自体は基本的に更新しない | 一部または全体を再学習する場合がある |
| 適したケース | 回答スタイルや判断基準を変えたい場合 | 最新情報や社内文書を参照したい場合 | 近いタスクに素早く転用したい場合 |
| 代表的な用途 | チャットボットの口調統一、分類精度向上、専門用語対応 | 社内FAQ、規定検索、マニュアル検索 | 画像分類、文章分類、固有表現抽出 |
使い分けの基本は、次の通りです。
- AIの回答スタイルや判断基準を変えたい場合:ファインチューニング
- 最新情報や社内文書を参照させたい場合:RAG
- 既存モデルを近いタスクに素早く転用したい場合:転移学習
すべてをファインチューニングで解決しようとすると、開発コストやデータ準備の負担が大きくなります。まずは目的を明確にし、最小限の手法から検討することが重要です。
RAG(検索拡張生成)との使い分け
ファインチューニングとRAGは、企業の生成AI導入で特に比較されやすい手法です。
RAGは、外部データベースや社内文書を検索し、その情報をもとにAIが回答する仕組みです。検索拡張生成とも呼ばれます。
たとえば、次のような用途ではRAGが適しています。
- 社内規定を参照するAIチャットボット
- 最新の製品情報を回答するFAQシステム
- 契約書やマニュアルを検索して回答する業務支援AI
- 頻繁に更新されるナレッジを扱う問い合わせ対応
RAGの強みは、情報を更新しやすい点です。モデルを再学習させなくても、参照するデータベースや文書を更新すれば、回答に反映しやすくなります。
一方、ファインチューニングは、AIモデルの出力傾向や判断基準を調整する方法です。次のような用途に向いています。
- 自社の回答トーンを統一したい
- 特定の専門用語を自然に扱わせたい
- 定型的な分類や判定を高精度に行わせたい
- プロンプトだけでは安定しない出力形式を学習させたい
簡単に言えば、RAGは「必要な情報を外から探して答える仕組み」、ファインチューニングは「AIの考え方や答え方を自社向けに調整する仕組み」です。
最新情報の参照が重要な場合はRAG、回答スタイルや判断基準の最適化が重要な場合はファインチューニングが適しています。
また、両者はどちらか一方だけを選ぶものではありません。たとえば、ファインチューニングで自社らしい回答スタイルを学習させたうえで、RAGによって最新の社内文書を参照させる構成も有効です。
このようなハイブリッド構成により、回答品質と情報の新しさを両立しやすくなります。
転移学習との使い分け
転移学習とは、あるデータで学習したモデルを、別の近いタスクに活用する手法です。
たとえば、一般的な画像分類モデルをベースに、特定製品の不良品検知に転用するようなケースが該当します。すでに画像の特徴を理解しているモデルを活かすため、ゼロから学習するよりも効率よく開発できます。
ファインチューニングと転移学習は近い概念として扱われることがありますが、厳密には焦点が異なります。
転移学習は、学習済みモデルの知識を別のタスクへ転用する考え方です。出力層など一部の層だけを再学習させるケースもあります。一方、ファインチューニングは、学習済みモデルの一部または全体のパラメータを微調整し、より深く特定タスクに適合させる方法です。
実務では、次のように使い分けると整理しやすくなります。
- 類似タスクへ素早く転用したい:転移学習
- 特定の業務や出力品質に深く合わせたい:ファインチューニング
- 専門性が高く、汎用モデルのままでは精度が不足する:ファインチューニング
AI導入の初期段階では、転移学習や既存モデルの活用で十分な場合もあります。より高い精度や業務特化が必要になった段階で、ファインチューニングを検討する流れが現実的です。
企業がファインチューニングを導入する3つのメリット
ファインチューニングのメリットは、単にAIの回答精度を高めることだけではありません。
ここでは、企業がファインチューニングを導入する主なメリットを3つ紹介します。
専門用語や特定ドメインへの最適化
ファインチューニングの大きなメリットは、汎用AIでは扱いにくい専門用語や業界固有のルールに対応しやすくなる点です。
一般的なAIモデルは、幅広い分野の知識を持っています。しかし、医療、法律、製造、金融、人材、物流などの専門領域では、一般的な知識だけでは正確な回答が難しい場面があります。
たとえば、次のようなケースです。
- 医療文書に含まれる専門用語を正しく分類したい
- 法律文書の条項を一定の基準で要約したい
- 製造業の検査画像から不良パターンを判定したい
- 金融レポートから企業名や人物名を正確に抽出したい
- 人材サービスで求人と求職者のマッチ理由を自然に説明したい
ファインチューニングでは、自社や業界に特化したデータを学習させることで、こうした専門領域への適応が可能になります。特に、汎用AIが「それらしいが正確ではない回答」をしてしまう業務では、ファインチューニングによる精度改善が有効に働く可能性があります。
ただし、専門データを入れれば必ず精度が上がるわけではありません。学習データの品質、タスク設計、評価方法が適切であることが前提です。
ゼロからの開発と比べたコスト・時間の大幅削減
ファインチューニングは、AIモデルをゼロから開発する場合と比べて、開発コストと期間を抑えやすい点もメリットです。
ゼロからAIモデルを構築するには、大量のデータ、計算資源、AIエンジニア、検証環境が必要です。特に大規模な生成AIモデルを自社で一から開発するのは、多くの企業にとって現実的ではありません。
一方、ファインチューニングでは、すでに基礎能力を持つ学習済みモデルを活用します。そのため、必要な範囲に絞って追加学習を行うことで、比較的少ないデータと計算リソースで業務特化型のモデルを作りやすくなります。
OpenAIの公式ドキュメントでは、ファインチューニングには最低10件の学習例が必要であり、50〜100件の高品質な例から改善が見られることが多いと説明されています。もちろん、必要なデータ量は用途や求める精度によって変わります。
このように、ファインチューニングは「ゼロから作る」のではなく「既存モデルを目的に合わせて調整する」ための手法です。そのため、PoCや小規模な業務改善から始めたい企業にとって、現実的な選択肢になりやすいといえます。
独自ブランドの応答スタイルの確立
ファインチューニングは、知識や精度の改善だけでなく、AIの回答スタイルを整える目的でも活用できます。
たとえば、コールセンターやチャットボットでは、回答内容が正しいだけでなく、企業のブランドイメージに合っていることも重要です。次のような観点をAIに学習させることで、対応品質のばらつきを抑えやすくなります。
- 丁寧だが硬すぎない口調
- 顧客に不安を与えない説明順序
- 問い合わせ分類ごとの対応フロー
- 使用してよい表現、避けるべき表現
- 自社サービスらしいトーン&マナー
プロンプトで細かく指示する方法もありますが、毎回長い指示を入力すると、トークン消費量が増えたり、出力が安定しにくくなったりする場合があります。
ファインチューニングによって、望ましい回答例をモデルに学習させることで、特定の出力スタイルを再現しやすくなります。特に、大量の問い合わせ対応や文章生成を行う企業では、回答品質の標準化と運用効率の改善につながる可能性があります。
【業界別】ファインチューニングを活用した成功事例
ファインチューニングは、生成AIの文章生成だけでなく、レコメンド、金融データ分析、画像認識など幅広い領域で活用されています。
ここでは、公開情報で確認できる事例をもとに、業界別の活用イメージを紹介します。
【人材業】Indeed
Indeedでは、求職者に対して「なぜこの求人が自分に合っているのか」を説明する、パーソナライズされた文章生成にAIを活用していました。
しかし、大規模なユーザー基盤に対してFew-shot promptingで対応すると、プロンプトが長くなり、トークン消費量や運用コストが大きくなる課題がありました。
Few-shot promptingとは、AIにいくつかの回答例を提示し、その例に沿って出力させる方法です。手軽に利用できる一方で、毎回プロンプト内に例を含めるため、利用規模が大きくなるほどコストや処理効率が課題になりやすくなります。
そこでIndeedは、OpenAIと連携し、小型のGPTモデルをファインチューニングしました。求人と求職者の文脈に合った説明を生成できるように調整することで、同等の出力品質を維持しながら、使用トークン数を60%削減したと紹介されています。
大規模サービスにおいて、ファインチューニングが精度改善だけでなく、トークン削減やレスポンス効率の改善にもつながる事例です。
【金融業】Capital Fund Management
Capital Fund Managementでは、金融データに含まれる企業名、人物名、組織名などの固有表現を正確に抽出するため、NERモデルの精度向上に取り組んでいました。
NERとは、Named Entity Recognitionの略で、文章中から企業名、人名、地名、組織名などの固有表現を抽出する技術です。
金融領域では、一般的な文章と比べて専門用語や固有名詞が多く、文脈の判別が難しいケースがあります。そのため、汎用的な自然言語処理モデルだけでは、抽出精度や運用コストに課題が生じやすくなります。
Capital Fund Managementの事例では、LLMを活用したラベリングとデータ改善を行い、金融データ向けに小型モデルをファインチューニングしました。公開情報では、精度を6.4%改善し、大規模LLMのみを使う場合と比べて最大80分の1のコストで運用できる可能性が示されています。
【交通サービス業】Grab
Grabでは、東南アジア地域の地図データを高精度に整備するため、道路標識、車線数、速度制限標識などを画像から正確に読み取る必要がありました。しかし、地域ごとに道路環境や標識の見え方が異なり、汎用的な画像認識モデルだけでは十分な精度を出しにくい課題がありました。
そこでGrabは、GPT-4oのビジョンファインチューニングを活用し、道路画像に含まれる車線や標識をより正確に認識できるようにモデルを調整しました。
OpenAIの公開事例では、車線カウントの精度が20%向上し、速度制限標識の特定も13%改善したと紹介されています。地図作成の手作業を減らし、データ品質の向上と運用コスト削減につなげた事例です。

企業がファインチューニング導入する4ステップ
ファインチューニングを導入する際は、いきなり学習データを用意するのではなく、目的、モデル、データ、評価方法を順番に整理することが重要です。
ここでは、ファインチューニング導入の基本的な流れを4ステップで解説します。
目的の明確化とベースモデルの選定
最初に行うべきことは、ファインチューニングで解決したい課題を明確にすることです。
目的が曖昧なまま進めると、どのデータを集めるべきか、どのモデルを選ぶべきか、何をもって成功と判断するかが不明確になります。
たとえば、次のように目的を具体化します。
- 社内問い合わせ対応の回答精度を上げたい
- 顧客対応チャットボットの口調を統一したい
- 契約書の分類精度を高めたい
- 製品画像から不良品を検知したい
- 求人推薦理由をユーザーごとに自然な文章で生成したい
目的が明確になったら、用途に合ったベースモデルを選定します。文章生成や対話であればGPTなどの大規模言語モデル、文章分類や固有表現抽出であればBERT系モデル、画像認識であればResNetやビジョン対応モデルなどが候補になります。
ただし、最初から高性能な大規模モデルを選べばよいとは限りません。処理速度、コスト、運用環境、必要な精度を踏まえて選ぶことが重要です。
データの収集と前処理(データクレンジング)
ファインチューニングで最も重要な工程の一つが、学習データの準備です。
AIは学習データの内容をもとに出力傾向を変えるため、データに誤りや偏りがあると、モデルの性能も下がりやすくなります。
準備するデータは、用途によって異なります。
- チャットボット:質問と理想的な回答のセット
- 文章分類:文章と分類ラベルのセット
- 固有表現抽出:文章と抽出対象のラベル
- 画像認識:画像と正解ラベル
- 文章生成:入力文と理想的な出力文のセット
データを集めたら、次のような前処理を行います。
- 重複データの削除
- 誤字脱字や表記ゆれの修正
- 個人情報や機密情報の除去
- 不要なノイズの削除
- 学習用、検証用、テスト用データへの分割
OpenAIのGPTモデルをファインチューニングする場合、公式ドキュメントでは最低10件の学習例が必要とされています。また、50〜100件の高品質なトレーニングサンプルから改善が見られることが多いとされています。
ただし、これはあくまで目安です。複雑な業務や高い正確性が必要な用途では、より多くのデータや継続的な改善が必要になる場合があります。
ハイパーパラメータの設定と学習の実行
データ準備が完了したら、学習条件を設定してファインチューニングを実行します。
このとき設定する学習条件を、ハイパーパラメータと呼びます。代表的なものには、学習率、バッチサイズ、エポック数などがあります。
それぞれの意味は次の通りです。
- 学習率:モデルをどの程度大きく更新するか
- バッチサイズ:一度に学習するデータ量
- エポック数:同じ学習データを何回繰り返し学習するか
これらの設定が適切でないと、学習が進まなかったり、訓練データに過度に適応したりすることがあります。
学習は、クラウド環境やGPU環境を利用して実行するのが一般的です。OpenAIなどのAPIを利用する場合は、所定の形式にデータを整えてアップロードし、ファインチューニングジョブを実行します。
学習中は、損失値や検証データでの精度を確認し、過学習の兆候がないかをモニタリングします。特に企業利用では、学習を実行する前に、利用するデータの取り扱い、セキュリティ要件、コスト見積もりを確認しておくことが重要です。
モデルの評価と継続的な改善
ファインチューニングは、学習を実行して終わりではありません。学習後のモデルが実運用に耐えられるかを評価し、必要に応じて改善を続ける必要があります。
評価では、次のような観点を確認します。
- 回答内容が正確か
- 意図した出力形式になっているか
- 専門用語を正しく扱えているか
- 誤回答や不自然な回答が増えていないか
- 既存モデルやプロンプト改善と比べて効果があるか
- コストに見合う改善が得られているか
テストデータを使って定量的に評価するだけでなく、実際の業務担当者による確認も重要です。業務上の正しさや顧客対応としての適切さは、数値だけでは判断しきれない場合があります。
期待した精度が出ない場合は、次のような改善を行います。
- 学習データの量を増やす
- 誤ったデータや品質の低いデータを除く
- 回答例の表現を統一する
- タスクを細かく分ける
- ハイパーパラメータを見直す
- RAGやプロンプト改善との併用を検討する
AIは一度作って終わりではなく、運用しながら改善するものです。ファインチューニング後も、利用ログや失敗例をもとに継続的に品質を高める体制が求められます。
ファインチューニング 導入時の3つのリスク・失敗要因とその対策
ファインチューニングは有効な手法ですが、導入すれば必ず成果が出るわけではありません。
ここでは、企業がファインチューニングを導入する際に注意すべきリスクと対策を解説します。
過学習(オーバーフィッティング)のリスク
過学習とは、AIモデルが学習データに過度に適応しすぎて、未知のデータに対して正しく対応できなくなる状態です。
たとえば、限られた問い合わせデータだけを学習させた結果、学習データに似た質問には正しく答えられるものの、少し表現が変わると誤った回答をしてしまうケースがあります。
過学習が起きる主な原因は次の通りです。
- 学習データの量が少なすぎる
- データの種類が偏っている
- 同じような例ばかりを学習している
- エポック数が多すぎる
- 評価用データを十分に用意していない
過学習を防ぐには、データの多様性を確保し、学習中の進捗を定期的に評価することが重要です。
具体的には、次のような対策が考えられます。
- 学習データとテストデータを分ける
- 実運用に近いデータで評価する
- 似た内容のデータに偏らないようにする
- 学習を途中で止める仕組みを取り入れる
- 小さく検証してからデータ量を増やす
ファインチューニングでは、学習データでの成績だけを見るのではなく、未知のデータに対する性能を確認することが重要です。
高品質な学習データ(教師データ)準備の壁
ファインチューニングで最も大きなボトルネックになりやすいのが、学習データの準備です。
AIに学習させるデータは、単に量が多ければよいわけではありません。正確で、一貫性があり、実際の業務に近いデータであることが重要です。たとえば、問い合わせ対応AIを作る場合、質問と回答のセットに次のような問題があると、モデルの品質が下がりやすくなります。
- 回答の言い回しが担当者ごとにばらばら
- 古いルールに基づいた回答が含まれている
- 誤った回答が混ざっている
- 重要なケースがデータに含まれていない
- 個人情報や機密情報が残っている
このようなノイズが含まれたまま学習させると、AIも誤った回答や不統一な対応を学習してしまいます。
対策としては、データクレンジングとアノテーションの品質管理が欠かせません。アノテーションとは、AIに学習させるために正解ラベルを付ける作業です。たとえば、問い合わせ文に対して「契約」「料金」「解約」などの分類ラベルを付ける作業が該当します。
具体的には、次のような取り組みが有効です。
- 業務担当者が正解データを確認する
- 回答ルールや表記ルールを先に決める
- 古いデータや誤ったデータを除外する
- 重要なパターンを網羅できているか確認する
- 必要に応じて外部の専門サービスを活用する
ファインチューニングの成否は、モデル選定よりもデータ準備で決まる場合があります。特に企業利用では、データの量だけでなく、品質と運用ルールを重視することが重要です。
専門知識を持つ社内リソースの不足
ファインチューニングには、AIやデータ活用に関する専門知識が必要です。特に、次のような工程では専門性が求められます。
- 課題に合ったベースモデルの選定
- 学習データの設計
- データクレンジング
- アノテーション設計
- ハイパーパラメータの調整
- 評価指標の設計
- セキュリティやガバナンスの確認
社内にAI人材が不足している状態で進めると、データ準備に時間がかかったり、期待した精度が出なかったりすることがあります。
また、ビジネス部門と開発部門の間で目的がずれることもあります。たとえば、ビジネス部門は「問い合わせ対応を効率化したい」と考えている一方で、開発側は「モデルの精度向上」だけを追ってしまうケースです。
対策としては、社内人材の育成と並行して、外部の専門家を活用することが有効です。特に、初期段階では次のような支援を受けることで、失敗リスクを抑えやすくなります。
- AI導入目的の整理
- PoC設計
- データ準備方針の策定
- モデル選定
- 評価指標の設計
- 運用体制づくり
自社だけで完結させることにこだわるよりも、必要な専門性を外部から補いながら、社内に知見を蓄積していく進め方が現実的です。
ファインチューニングの導入支援は「フリーコンサルタント.jp」へご相談ください
ファインチューニングを導入する際は、AIモデルの技術面だけでなく、業務課題、データ整備、運用体制まで含めて検討する必要があります。
特に企業では、次のような悩みが生じやすくなります。
- ファインチューニングとRAGのどちらを選ぶべきかわからない
- 自社データが学習に使える品質か判断できない
- AI導入のPoCをどのように設計すべきかわからない
- 社内にAIやデータ活用に詳しい人材が不足している
- 開発会社やツールベンダーとのやり取りを適切に進めたい
フリーコンサルタント.jpでは、企業のAI導入やDX推進に関する課題に応じて、外部プロ人材の活用を支援しています。
ファインチューニングを含むAI活用プロジェクトでは、構想段階からPoC設計、データ整備、開発ディレクション、運用改善まで、必要な専門性を持つ人材の参画が重要になります。
自社だけで判断するのが難しい場合は、まずは課題整理から始めることが有効です。AI導入の目的や現在のデータ状況を整理することで、ファインチューニングを行うべきか、RAGや既存ツールの活用で十分かを判断しやすくなります。

フリーコンサルタント.jpによるAI関連の支援事例
ここでは、AI活用に関連する支援事例を紹介します。
事例①
大手小売流通会社では、在庫管理において経験と勘に頼った予測を行っていたため、受発注業務に多くの工数がかかっていました。業務効率化に向けてAIによる需要予測の導入を進めたい一方で、プロジェクトを推進できる人材が不足しており、AI需要予測モデルの構築から関係者への説明までを担える体制が求められていました。
| 当時の課題 | ・在庫管理において、経験と勘に頼った予測が行われており、受発注業務に多くの工数がかかっていた ・業務効率化に向けてAIによる需要予測を導入したいが、プロジェクトを支援できる人材が不足していた ・AI需要予測モデルの構築に向けて、データの現状調査や企画書作成が必要だった ・AI需要予測に関する社内説明やプレゼン資料の作成を担う人材が求められていた |
| 実施したこと | ・AI需要予測モデル構築のPM経験を持つプロ人材をアサインした ・社内データの現状調査を行い、AI活用に向けた企画書作成を支援した ・社内データの取得、分析、AI需要予測モデル構築を推進した ・予測モデルの推進、運用に向けたプロジェクトマネジメントを支援した ・AI需要予測に関する社内プレゼン資料の作成を支援した |
その結果、これまで人が長時間かけて行っていた予測・在庫管理業務にAIを活用できるようになり、人的な作業時間の削減につながりました。また、在庫管理の予測精度が向上し、廃棄コストの改善にも貢献しました。
事例②
大手車載機器メーカーでは、AIを活用した車載プロダクトとクラウドを通信で連携させ、画像解析やリアルタイムでのデータ連携を行う新製品の開発プロジェクトを進めていました。一方で、AIやエッジコンピューティングなどの先進技術に関する知見に加え、プロダクト開発におけるプロジェクトマネジメント経験を持つ人材が不足していました。
| 当時の課題 | ・AIを活用した車載プロダクトとクラウドを連携させ、画像解析やリアルタイムデータ連携を行う新製品開発を進めていた ・AI、エッジコンピューティングなどの先進技術に関する知見を持つ人材が必要だった ・H/W、S/Wの両面を理解し、開発パートナーのコントロールまで担える人材が求められていた ・プロダクト開発だけでなく、上層部への提案やスキルトランスファーまで支援できる体制が必要だった |
| 実施したこと | ・AIを活用した新規事業企画や事業開発経験を持つプロ人材をアサインした ・AIの知見に加え、車載機器領域の経験も活かしながらプロジェクトを推進した ・プロダクトマネージャーとして、H/W、S/W両面の開発支援を行った ・開発パートナーのコントロールや各種ドキュメント作成を支援した ・上層部への提案、開発ノウハウの共有、スキルトランスファーを実施した |
その結果、プロダクトローンチまでのプロジェクトにおける業務支援を遂行し、AIを活用したサービス開発の推進に貢献しました。また、大規模プロジェクトにおける多岐にわたる業務を可視化・明文化し、プロジェクトマネジメントを担える社内人材の育成にもつながりました。
まとめ
ファインチューニングとは、既存の学習済みAIモデルに対して追加学習を行い、特定の業務や目的に合わせて性能を調整する手法です。
汎用AIを自社業務に最適化できるため、専門用語への対応、回答スタイルの統一、分類精度の向上などに役立ちます。
一方で、ファインチューニングは万能ではありません。最新情報を参照させたい場合はRAGが適していることもあり、類似タスクへの転用であれば転移学習や既存モデルの活用で十分な場合もあります。
ファインチューニングを成功させるには、AIモデルそのものだけでなく、データ準備、業務設計、運用改善まで含めた取り組みが欠かせません。
自社だけで判断が難しい場合は、AI活用に詳しい外部人材や専門家の支援を受けながら、まずは小さなPoCから始めることが有効です。






